Lesson 1: What is horizontal scaling
Typically, most network technologies use the Remote Procedure Call (RPC) method to organize interactions between objects over the network, which seeks to mask the differences between local and remote object calls. This approach is based on the idea that the local programming model is simpler, so it is preferable if the programmer uses it and the internal implementation provides transparency for remote interactions.
This method works well for point-to-point connections, but is not appropriate for large scale network applications, as you will see in the next section. The Proto.Actor platform takes a different approach to scaling applications. It combines the best features of other approaches, so we get relative transparency of remote interactions and we can use the same application code with actors - next you will see for yourself that the code at the top level remains the same.
Before going deeper into scalability, we should take a brief look at the terminology used and some examples of network topology.
Common terminology.
By node in this chapter we will mean an existing application that supports the ability to exchange data over a network. It is a connection point in the network topology. It is part of a distributed system. Several nodes can be run on one physical server or on several servers. The figure shows some typical network topologies.
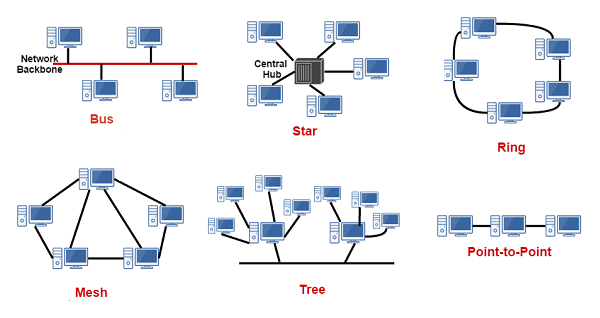
The node has a specific role in the distributed system. It is responsible for specific tasks. For example, a node may be part of a distributed database or one of several web servers that provide access to the system through a web interface.
The node uses a specific transport Protocol for interactions. For example, such transport protocols can be TCP/IP and UDP. Messages sent by nodes to each other using the transport Protocol must be encoded and decoded into Protocol data units. Data blocks contain a binary representation of messages in the form of byte arrays. Serialization and deserialization procedures are used to convert messages to bytes and back, respectively. For this purpose, the Proto.Actor platform has its own serialization module, which we will briefly discuss in this module.
Nodes that are part of one distributed system are members of the group. Membership can be static or dynamic (or even mixed). In the case of static membership, the number of nodes and each node’s role are fixed and cannot be changed throughout the life of the network. Dynamic membership allows nodes to play different roles and also connect to and disconnect from the network.
Static membership, as you understand it, is easier to implement. All hosts communicate with other hosts on the network with connections that have been installed at startup. But it is also less flexible because a node cannot simply be replaced by another node running on another machine with a different network address.
Dynamic membership is more flexible and allows node groups to grow and reduce as needed. It allows you to restore the network’s overall performance when some nodes fail, by automatically replacing them with other nodes. But it is also more difficult to implement. Dynamic membership requires the implementation of a mechanism to join or leave a group dynamically. To detect and fix failures, detect unavailable/disabled nodes, and provide some detection mechanism that will help new nodes find a group in the network. Because at the dynamic membership of network addresses are determined dynamically, not statically.
Reasons for using the distributed programming model.
If we want to deploy our application on multiple servers to increase performance. With the use of the local programming model, we will face four major problems.
- Latency - the presence of a network between interacting objects requires a lot of time to transmit each message. The approximate time to extract a message from the L1 cache is something like 0.5 ns. The extraction time from the main memory is about 100 ns. And it takes about 150 ms to transfer a packet from the Netherlands to California. You can also add delays due to high traffic during peak hours, packet retransmission, disconnections, etc.
- Partial failure - determining the performance of all parts of a distributed system is a complex task, especially when some parts of the system are not permanently available, may shut down and reappear.
- Memory access-the operation of getting a reference to an object in memory on a local system cannot be interrupted, unlike a distributed system.
- Competition - there is no single “owner,” so the sequence of messages may be broken due to the factors listed above.
Because of these problems, the local programming model’s usage in a distributed environment is failing. But Proto.Actor platform offers to use a distributed model for both kinds of environments - distributed and local. It is necessary to notice that the distributed programming model simplifies the creation of the distributed applications, but can make local programming the same difficult, as distributed.
But times have changed. Two decades later, we have to deal with multi-core processors. And more and more tasks have to be solved in a distributed cloud. The advantages of using the distributed programming model to create local systems are that it simplifies competitive programming, as you could see in the previous chapters. We are already used to asynchronous interactions, have learned how to deal with partial failures, and are using a generalized approach to competitive execution, simplifying our programming for multi-processor systems and preparing us for the transition to a distributed environment.